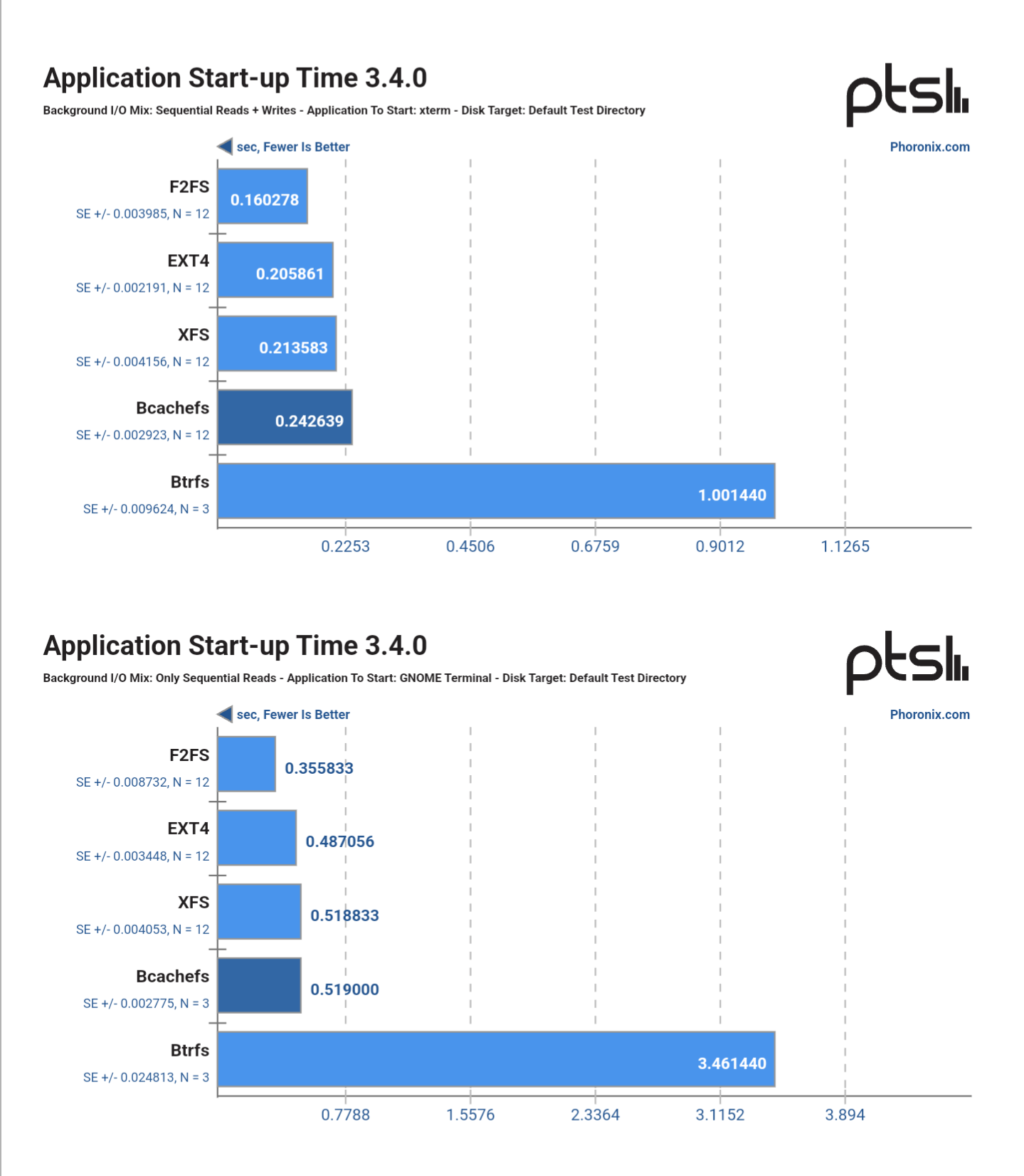
It’s mostly better, but not in every way. It has a lot of useful features, at a performance cost sometimes. A cost that historically wasn’t a problem with spinning hard drives and relatively slow SATA SSDs but will show up more on really fast NVMes.
The snapshots, it has to keep track of what’s been modified. Depending on the block size, an update of just a couple bytes can end up as a few 4k write because it’s Copy-on-Write and it has to update a journal and it has to update the block list of the file. But at the same time, copying a 50GB file is instantaneous on btrfs because of the same CoW feature. Most people find the snapshots more useful than eeking out every last bit of performance out of your drive.
Even ZFS, often considered to be the gold standard of filesystems, is actually kinda slow. But its purpose isn’t to be the fastest, its purpose is throwing an array of 200 drives at it and trusting it to protect you even against some media degradation and random bit flips in your storage with regular scrubs.
A couple nits to pick: BTRFS doesn’t use/need journaling because of its CoW nature - data on the disk is always correct because it doesn’t write data back over the same block it came from. Only once data is written successfully will the pointer be moved to the newly-written block. Also, instantaneous copies from BTRFS are actually due to reflinking instead of CoW (XFS can also do reflinking despite not being CoW, and ZFS didn’t have this feature until OpenZFS 2.2 which just released).
I agree with the ZFS bit and I’m firmly in the BTRFS/ZFS > Ext4/XFS/etc camp unless you have a specific performance usecase. The ability to scrub checksums of data is so invaluable in my opinion, not to mention all the other killer features. People have been running Ext4 systems for decades pretending that if Ext4 does not see the bitrot, the bitrot does not exist. (then BTRFS picks up a bad checksum and people scold it for being a bad filesystem)
People have been running Ext4 systems for decades pretending that if Ext4 does not see the bitrot, the bitrot does not exist. (then BTRFS picks up a bad checksum and people scold it for being a bad filesystem)
ZFS made me discover that my onboard SATA controller sucks and returns bad data occasionally under heavy load. My computer cannot complete a ZFS scrub without finding errors, every single time.
Ext4, bcache and mdadm never complained about it, ever. There was never any sign that something was wrong at all.
100% worth it if you care about your data. I can definitely feel the hit on my NVMe but it’s also doing so much more.
A file system and a raid setup all in one with facebook’s code for de-/compression … yet another piece of software that tries to do the work for several others.
ext4 will rarely have extreme loads unless all you do is backup and mirroring. For more accurate data read/write and better checks use xfs and external journaling. On M2 it is by far the fastest solution and far more secure than ext.
On magnetic disk there is physical location for each bit of data written, for ssd it is all virtual space handled by internal software simulating a magnetic drive. The variation from disk to disk is much higher than the sensitivity of the fs.
You want accuracy and reliability of data storage, use HDD and Raid!
RAID doesn’t checksum and heal the rotten data. It’s game over before you even have a filesystem on top of it, because said filesystem can’t directly access the underlying disks because of the RAID layer.
Errors will occur, and RAID has no way of handling it. You have a RAID1, disk 1 says it’s a 0, disk 2 says it’s a 1. Who’s right? RAID can’t tell, btrfs and ZFS can. RAID won’t even notice there’s a couple flipped bits, it’ll just pass them along. ZFS will just retry the read on both disks, pick the block that matches the checksum, and write the correct data back on the other disk. That’s why people with lots of data loves ZFS and RAIDZ.
The solution isn’t more reliable hardware, the solution software that can tell you and recover from your failing hardware.

{kind=link}
It’s mostly better, but not in every way. It has a lot of useful features, at a performance cost sometimes. A cost that historically wasn’t a problem with spinning hard drives and relatively slow SATA SSDs but will show up more on really fast NVMes.
The snapshots, it has to keep track of what’s been modified. Depending on the block size, an update of just a couple bytes can end up as a few 4k write because it’s Copy-on-Write and it has to update a journal and it has to update the block list of the file. But at the same time, copying a 50GB file is instantaneous on btrfs because of the same CoW feature. Most people find the snapshots more useful than eeking out every last bit of performance out of your drive.
Even ZFS, often considered to be the gold standard of filesystems, is actually kinda slow. But its purpose isn’t to be the fastest, its purpose is throwing an array of 200 drives at it and trusting it to protect you even against some media degradation and random bit flips in your storage with regular scrubs.
A couple nits to pick: BTRFS doesn’t use/need journaling because of its CoW nature - data on the disk is always correct because it doesn’t write data back over the same block it came from. Only once data is written successfully will the pointer be moved to the newly-written block. Also, instantaneous copies from BTRFS are actually due to reflinking instead of CoW (XFS can also do reflinking despite not being CoW, and ZFS didn’t have this feature until OpenZFS 2.2 which just released).
I agree with the ZFS bit and I’m firmly in the BTRFS/ZFS > Ext4/XFS/etc camp unless you have a specific performance usecase. The ability to scrub checksums of data is so invaluable in my opinion, not to mention all the other killer features. People have been running Ext4 systems for decades pretending that if Ext4 does not see the bitrot, the bitrot does not exist. (then BTRFS picks up a bad checksum and people scold it for being a bad filesystem)
ZFS made me discover that my onboard SATA controller sucks and returns bad data occasionally under heavy load. My computer cannot complete a ZFS scrub without finding errors, every single time.
Ext4, bcache and mdadm never complained about it, ever. There was never any sign that something was wrong at all.
100% worth it if you care about your data. I can definitely feel the hit on my NVMe but it’s also doing so much more.
@Max_P @yote_zip
A file system and a raid setup all in one with facebook’s code for de-/compression … yet another piece of software that tries to do the work for several others.
ext4 will rarely have extreme loads unless all you do is backup and mirroring. For more accurate data read/write and better checks use xfs and external journaling. On M2 it is by far the fastest solution and far more secure than ext.
@Max_P @yote_zip
On magnetic disk there is physical location for each bit of data written, for ssd it is all virtual space handled by internal software simulating a magnetic drive. The variation from disk to disk is much higher than the sensitivity of the fs.
You want accuracy and reliability of data storage, use HDD and Raid!
RAID doesn’t checksum and heal the rotten data. It’s game over before you even have a filesystem on top of it, because said filesystem can’t directly access the underlying disks because of the RAID layer.
Errors will occur, and RAID has no way of handling it. You have a RAID1, disk 1 says it’s a 0, disk 2 says it’s a 1. Who’s right? RAID can’t tell, btrfs and ZFS can. RAID won’t even notice there’s a couple flipped bits, it’ll just pass them along. ZFS will just retry the read on both disks, pick the block that matches the checksum, and write the correct data back on the other disk. That’s why people with lots of data loves ZFS and RAIDZ.
The solution isn’t more reliable hardware, the solution software that can tell you and recover from your failing hardware.